The journey to writing a chess engine
Introduction
My programming journey began in high school at the algorithm club.
We were around five people in the room and the club's president was a student of my age.
The goal was to learn just enough C, a programming language, to grind our way through the International Olympiad in Informatics problems. This was later known as competitive programming but I didn't know the term back then and saw this only as solving programming puzzles.
Turns out I was really bad at it. I recall that the student in charge once sat next to me to help me debug my program. He found multiple critical mistakes in my code, and it still wasn't working.
In the end he found out that we weren't even compiling the right file, only an old copy of the one we were looking at. No wonder it wouldn't work even with his advice !
However I wasn't really there to solve clever algorithmic problems. I actually wanted to make a program that could play chess with me.
I wasn't a good chess player either. It's just that I happened to know it was possible to make such a program and I found everything about AI immensely intriguing and cool.
That same student told me that using the same algorithm (minimax) as for the program I just made to play tic-tac-toe, I could probably make an AI that calculated four moves ahead.
That was around 2008, and I never found the will or the time to start the project.
In 2018, I found out about the chess programming wiki and decided to start working on it. I hadn't used C since my school years and found it difficult to make even a basic program work. After battling with it for more than one month, I decided that I was a poor C developer and stopped.
It wasn't until may 2022 when I came across Sunfish, a chess engine written in pure Python capable of playing at around 2000 rating on Lichess, that I decided to give another shot at coding my chess engine, but with Python this time. My roommate was playing a lot of chess at that time and had become better than me. I decided that a fun way to compete with him could be through a chess engine of my creation. Since my only perceived obstacle had been using C, I confidently proclaimed that within a month, my AI would defeat him.
I was wrong.
The bitter lesson in chess AI
How do we make a software that plays chess?
It's very difficult to implement some sense of strategy into the machine. For that, we would need to formalize the concept of it. We could eventually do it for a subset of problems that can arise in chess positions like questions around some pawn formations, the safety of our king in some positions, avoiding getting our pieces pinned... But this already difficult task becomes impossible as the list of strategic and tactical concepts increases as well as the interactions between them.
The formalization of those would not even easily lead to something that would produce or help us select the best move in a given position.
So what do we do ?
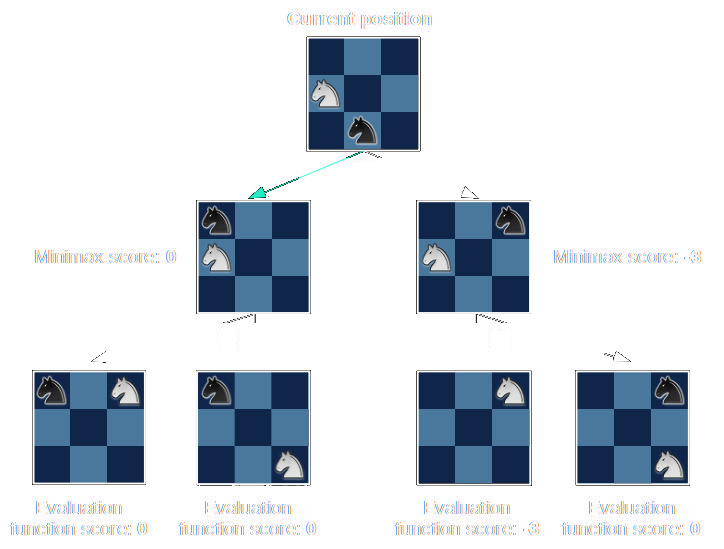
In solving complex problems like chess, it's often helpful to start with a simple, less elegant solution before attempting more sophisticated methods. One approach for chess is to simulate all possible paths from a given position and choose a path that guarantees a win (or at least a draw), assuming both players make perfect moves. "Perfect" here means that each player can choose their move based on complete knowledge of all possible paths.
However, the sheer number of paths in chess makes it impossible to consider all of them. To address this, we can limit our search to a certain number of decisions, resulting in a partial tree of paths. Instead of having a clear outcome at the end of each path (win, lose, or draw), we assign an estimated score to each position. Then, we choose the path that leads to the best possible outcome, given "perfect" play by both players (with "perfect" now defined within the context of our partial tree).
This approach is known as the minimax algorithm because we aim to maximize our score while our opponent tries to minimize it. By balancing out our own gains with our opponent's potential advantages, we can make informed decisions on the best moves to play in a game of chess.
This algorithm is the basis for classical engines, even Deep Blue, that defeated in 1997 the greatest chess player of the time, Kasparov, used similar mechanisms.
By using a "dumb" algorithm which systematically explores and evaluates game positions, chess engines can achieve remarkable performance levels. This demonstrates the effectiveness of harnessing the immense computational capabilities of machines to solve complex problems, such as finding the best moves in chess.
The minimax algorithm can be seen as an example of how a simple, computationally-driven approach can outperform solutions based on human knowledge and handcrafted features. This highlights the key message of an article written by Richard Sutton "The Bitter Lesson", which emphasizes the importance of leveraging computation and search to drive progress in artificial intelligence, rather than solely relying on the nuances of human expertise.

How difficult is it to create a chess AI ?
Implementing the minimax algorithm may seem straightforward, and in some ways, it is. The basic concept can be expressed in just a few lines of code. However, the primary challenge lies in its speed, as the chess game has an enormous search space. For a given position, there are usually around 30 possible moves to consider (given that most games end before the 40 ply mark). We often refer to the number of decisions made by all players in a path as the depth of the path. The more depth we have in our search, the more accurately we can predict the best move. But with each unit of depth, the number of paths to evaluate increases exponentially, roughly 30-fold.
This growth in computational complexity quickly becomes overwhelming. For instance, if our program calculates the minimax at depth 1 in 0.01 seconds, it would take 0.30 seconds for depth 2, 9 seconds for depth 3, 4.5 minutes for depth 4, and more than 2 hours for depth 5. In online matches, time controls are often around 5+3. That means that each player has a total of 5 minutes to make all of their moves, with an additional 3 seconds added to their clock after each move. This limited time budget per move forces us to operate at depth 3 in our example.
The correlation between depth of search and strength of a program is heavily dependent on the heuristic evaluation. To beat a standard regular player, a simplistic heuristic would require a depth of around 6 or 7, so we need to be much, much faster. In the world of programming, it is often only a tiny fraction of the code that is responsible for the performance of the whole application. Most of the time, if we can divide by ten or even by two the time it takes to do something, it's already a great success. Here we need to be 30 times faster for each additional depth we want to pick up and almost the whole codebase has some responsibility in the overall performance.
And that's not all: each speed improvement makes the code increasingly complex, with diminishing returns in terms of performance gains. We must carefully consider our code's structure, interactions between components, and proper testing of each change.
It's similar to constructing the tallest building possible, where each additional meter introduces new challenges, such as accounting for wind effects or designing more efficient elevator systems.
The recursive nature of the minimax algorithm adds another layer of difficulty. Writing the algorithm in a recursive manner causes the program to call itself at each depth it advances. This structure can be challenging to grasp, as a single line of code can have cascading effects on subsequent depths. Debugging such an algorithm is complex, since each function call creates a new instance with its own set of parameters and variables. Identifying the source of errors and tracing them back to their origins can be a daunting task.
There is a wealth of information online about building chess engines, including the well-known chess programming wiki, which offers code examples, concept explanations, and historical context. The source code for the best engines is even available on GitHub. How difficult could it be to simply replicate what we see and incorporate it into our own code? The catch is that, conceptually, every part of a chess engine is not overly difficult to understand. However, these components must work in harmony, and some only make sense when others reach a certain level of performance. Imagine building a car by gathering parts from various sources: you might obtain an F1 engine, but if it's paired with standard car tires and the aerodynamic profile and weight of a truck, it won't perform optimally.
The components of your engine must work together, and their interactions will become increasingly intertwined over time. You can study ideas used in other engines and test them in your own, but their effectiveness in improving your engine's strength is not guaranteed.
Inside a Chess Engine
Modern chess engines can be divided into two major categories: "classic" engines that utilize variations and improvements of the minimax algorithm, and those that leverage recent advancements in neural network training. Some engines may also blend elements from both approaches. To better understand these distinctions, we'll examine the components of a classical chess engine before briefly exploring the differences in machine learning (ML) based engines.
The foundation of a classical engine is the ability to generate all possible positions at a given depth, as well as the moves required to reach them. This information is used to construct a tree of possible moves, allowing the engine to decide the best course of action based on the evaluation of future positions. For each node (a specific position in the tree), all possible moves and their corresponding positions must be generated, enabling further exploration of new nodes. Move generation must be both accurate and fast since millions of nodes will be generated that way. It forms the basis of the engine's computational ability and impacts search techniques as some are only efficient if we reach a certain speed.
Another critical component of a chess engine is the evaluation function. Since it is not feasible to explore the entire tree of possible moves down to the end of a game, the search is limited to a certain depth. This requires estimating potential outcomes based on the current position. The evaluation function typically considers material balance (among other factors), with a positive count indicating a favorable position for white and a negative count favoring black.
Chess engines commonly express evaluation in centipawns, where one centipawn equals one-hundredth of a pawn's value. An advantage of 100 centipawns can generally force top players into a defensive stance, aiming for a draw, while an advantage of 300 centipawns is often insurmountable. If the evaluation is close to 0, the game is considered evenly balanced.
The evaluation function must be fast, as it will be applied to each terminal node in the tree at the maximum chosen depth. Its speed also influences search strategies and can be utilized in other aspects of the chess engine, such as ordering moves by potential. Early chess engines often featured complex evaluation functions packed with specific chess knowledge. However, as time passed, it became clear that a simpler yet faster evaluation function was more effective, as increased search depth would compensate for any shortcomings. This evolution is another example of "The Bitter Lesson".
Additional components of a classical chess engine focus on optimizing the search process, caching results to eliminate duplicated computations, and enhancing search outcomes within a given time frame.
For many years, ML techniques were deemed too slow for use in chess engines. However, this perception shifted in the past decade due to several advancements. Firstly, programs were adapted to leverage the massive parallel computational capabilities of graphics cards, which benefited some ML techniques. Additionally, certain neural networks were developed to be exceptionally fast when the structure of the input remained relatively consistent. These neural networks are now used in some top chess engines.
Stockfish is one of those engines that made the switch in july 2020.

Incorporating these specialized neural networks does not significantly alter the overall structure of the engine as they effectively replace the standard evaluation function. Although this method of evaluating positions is somewhat slower than the traditional approach, it offers greater precision. In top engines that evaluate positions at high depths, the increased depth's value is less crucial than in shallower searches, making the trade-off well worth it.
My journey
I began by examining the code of Sunfish, the only classic chess engine in Python I knew at the time. However, I now believe that Sunfish isn't an ideal model for creating our own engine, as it was designed to be as compact as possible, making the code relatively hard to follow. Additionally, it has very few tests, which are crucial for writing an engine.
Since I thought initially that I could beat myself (and my roommate) in less than a month, I didn't write any tests and dove head-first into all the components. This approach proved to be problematic, as defects in move generation emerged later on, and having everything intertwined made debugging very difficult. This also meant I would only find mistakes at a later stage. Since everything seemed flawed, how could I recognize that the engine was making decisions based on an incorrect game model? The issues could always be attributed to the slowness of the engine.
There isn't much information online about the kind of strength our engine should achieve during its development, and the few instances that exist are hard to compare due to different choices, including programming languages. Moreover, since every part of the engine is initially easy to improve, it could become stronger without truly addressing any issues. As a result, I was essentially blind to the fundamental problems hidden throughout my code.
After nine months of struggling I was exhausted, I felt I couldn’t go further, so I decided it was time to organize a match between my roommate and my engine. I suspected it would probably fail since I had played against it before. The engine made understandable moves but occasionally blundered. Exhausted, I felt I couldn't go further.
On New Year's Eve, they played a best-of-five match with a 5+3 time control. "Herald" (the name of my chess engine) executed some interesting moves and put up a fight. I wasn't as ashamed of the result as I initially feared. However, it blundered as expected in multiple games, losing 3 to 1 in the end. It achieved one win by avoiding obvious mistakes and my roommate being somewhat careless.
Although it lost, the match was entertaining, and the tension was palpable. The frustration led me to decide to give it another go.

I modularized every part of the code and committed to thoroughly testing them this time. My idea was that if it made no obvious mistakes, it could win without being faster. I first examined move generation, the easiest part to test. A standard test called "perft" involves generating all positions at a specific depth from a given one and comparing them to known results. If the numbers match, the move generation algorithm is correct. However, I hadn't implemented en passant or sub-promotions (promotions to pieces other than a queen). I had to implement en passant and limit test cases to positions without promotions. In some cases, I manually verified the correct result without sub-promotions.
I spent considerable time on this, discovering numerous mistakes in my move generation algorithm. It was difficult to notice when observing the bot play because it didn't select those moves. It was at this moment that I realized that it was not just a simple hobby anymore but a genuine engineering endeavor. It was my first time implementing tests in a personal project.
Since every module of the program was fragile and uncertain, I had no choice but to take the time to verify each one individually. And once tests are written and comprehensive enough to trust one bloc, you can rely on them to test other parts.
Unfortunately, not everything is easy to test. For example, the implementation of an algorithm to optimize the tree search is challenging to verify. Is algorithm B better than algorithm A? If it's meant to give the same result in less time, we can at least test that it yields the same result. Testing performance is difficult because it depends on the machine and its concurrent tasks. I attempted some tests to ensure it would do the same thing, exploring fewer nodes, but if the nodes were explored more slowly, it didn't help much.
If the new algorithm doesn't yield the same results, the only solution is a self-play test. Just have the two versions play each other and keep the best. But many questions arise from this simple idea. Which time control should I use? A faster one leads to more test games, but a slower one is closer to a real match. Maybe the new algorithm performs better only at slower time controls? Since the engine is deterministic, it will always play the same game for a given time control. I therefore decided to select a list of starting positions for more results, but this slowed down the tests again.
The tests, like the engine's code itself, involve a series of trade-offs. That's what makes creating a chess engine difficult.
Two months after the first match, we held a second encounter between my roommate and Herald. I knew Herald would win this time, based on its previous online matches, but it was still important to have an official end. As predicted, it won 3-0 effortlessly. However, the tension was absent. Friends present for the first match hardly looked at the board, and we casually discussed other topics. They didn't know how many hours I had poured into that moment and how much it meant to me.
Herald had won at last, but I still felt mixed up. The journey had been long and often lonely. I was going after a goal that I hadn't really defined in the beginning. My 'bitter lesson' was that I didn't really know what victory I was aiming for. Was it a fast win, the fun of shared excitement, or learning from a challenge? Even though I was happy about winning, I was left with a sour feeling because I didn't really know what I was chasing from the start.